MySQL Reverse ETL Source
UpdatedImport data from MySQL to any destination. This source saves you the trouble of writing code to extract, transform, and load data from your database. Instead, specify the query (or queries) to run, and we’ll handle the rest.
Best Practices
Before you add a Reverse ETL source, you should take some measures to ensure the security of your customers’ data and limit performance impacts to your database and Customer.io workspace.
Create a new database user/service account. Implement a database user with minimal privileges specifically for Customer.io import/sync operations. This person only requires read permissions with access limited to the tables you want to sync from.
Avoid using your main database instance. Consider creating a read-only database instance with replication in place, lightening the load and preventing data loss on your main instance.
Sync only the data that you’ll use in Customer.io. Limiting your query can improve performance, and minimizes the potential to expose sensitive data. Select only the columns you care about, and make sure you use the
{{last_sync_time}}to limit your query to data that changed since the previous sync.Limit your sync frequency so you don’t sync more than necessary and consume unnecessary resources. If the previous reverse ETL operation is still in progress when the next interval occurs, we’ll skip the operation and catch up your data on the next interval. You should monitor your first few reverse ETL intervals to ensure that your sync doesn’t impact your system’s security and performance—frequently skipped operations may indicate that you’re syncing too often.
Sending excessive data can impact your account’s performance
You should not run queries that return large data sets—millions of rows—more than once per day. Doing so may impact workspace performance, including delaying campaigns and messages.
Granting us access to your database
We officially support MySQL 5.7 and newer. An older database version might work, but we can’t guarantee it.
We support both SSL and non-SSL database connections. As a part of setup, you’ll need to provide the credentials of a database user with read-access to the tables you want to select data from.
If you use a firewall or an allowlist, you must allow the following IP address so that we can connect to your database.
| Account region | IP Address |
|---|---|
| US | 34.29.50.4 |
| EU | 34.22.168.136 |
Add your MySQL source
As a part of this setup, you’ll provide Customer.io with MySQL user credentials that we’ll use to query your database. We recommend that you create a new user with Read Only access specifically for Customer.io, so you can manage Customer.io access to your database independent of any other MySQL users you have.
Your database must allow connections from 34.29.50.4 or 34.22.168.136 if your account is in our EU region. If our IP address is blocked, we won’t be able to connect to your database.
In the Data Pipelines tab, click Sources.
Click Add Source and select MySQL.
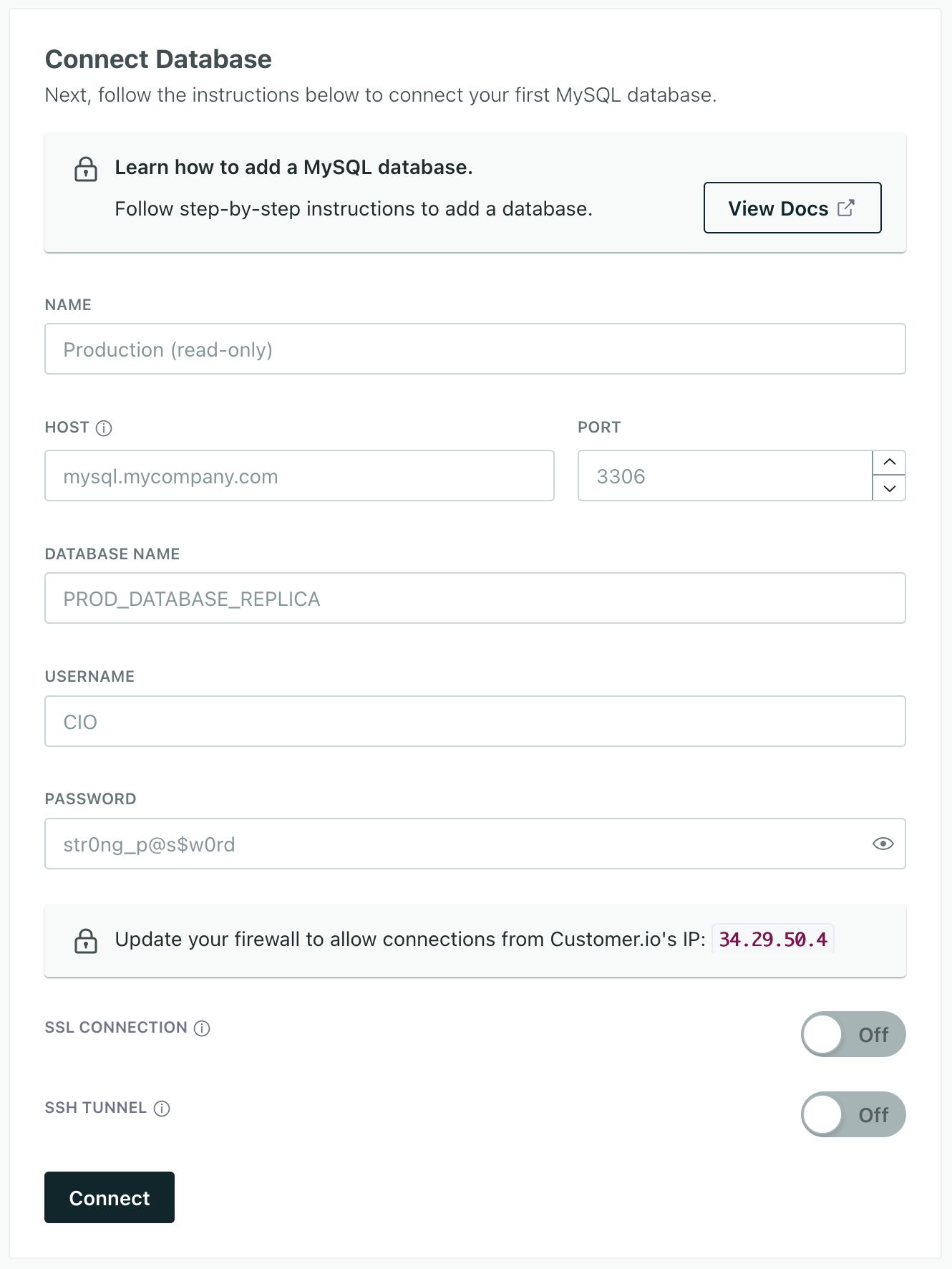
Provide your database information, including credentials to connect to your database, and click Save database.
- The Name is a friendly name you’ll use to recognize your database whenever you reference it in Customer.io.
- Enter Host address and the name of the database you want to connect to.
- Enter a database user’s credentials and click Add database. We suggest that you use someone with read-only credentials for your database. While our source integration won’t write to your database, using read-only credentials ensures that you can’t inadvertently make changes to your database through your query.
- Toggle the options for SSL or SSH tunneling if necessary.
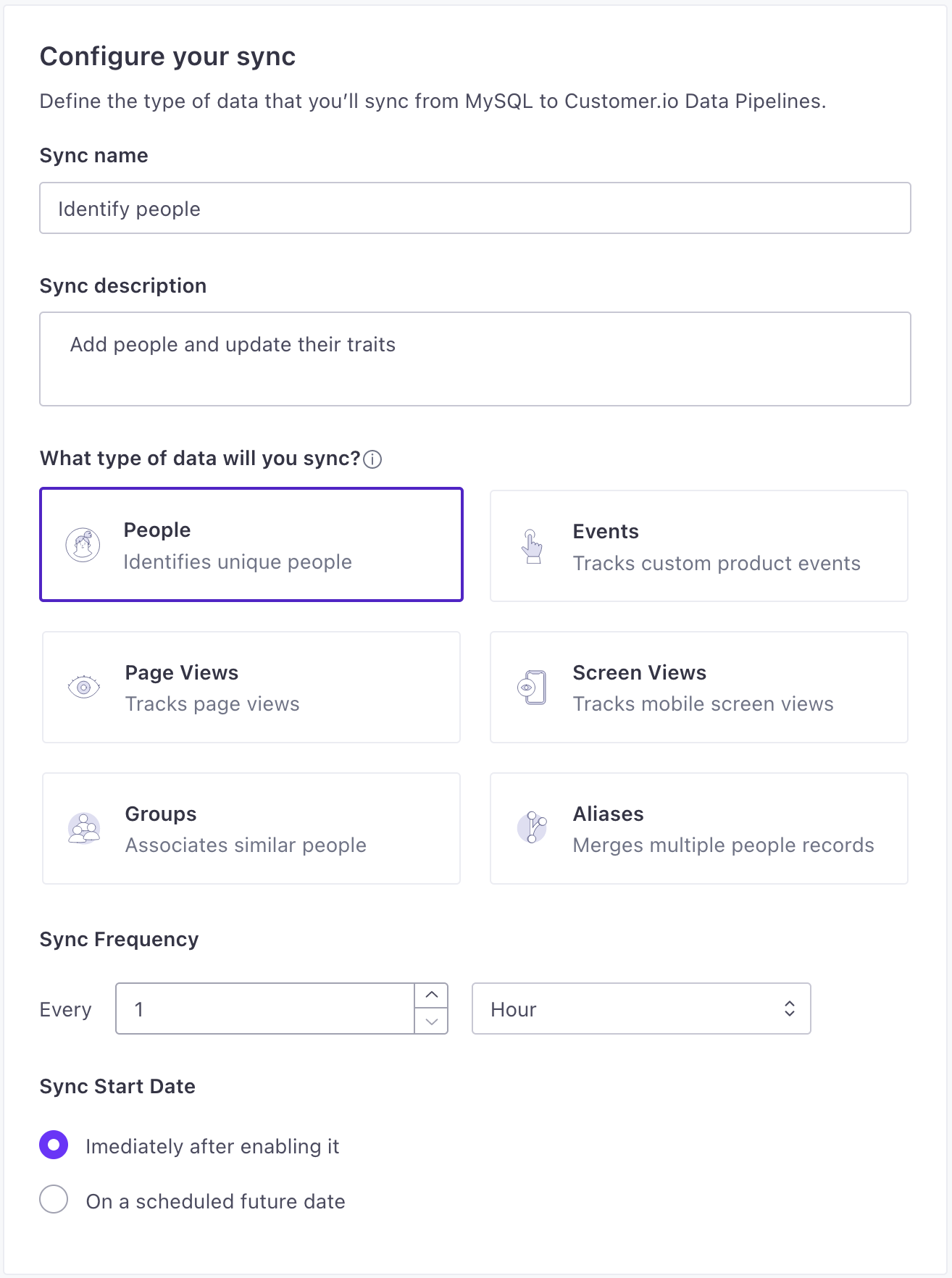
Set up a Sync. A sync is the type of source data (
identify,track, etc) you want to import from your database and click Next: Define Query. You can set up syncs for each type of data you want to import for your source.- Provide a Name and Description for the sync. This helps you understand the sync at a glance when you look at your source Overview later.
- Select the type of data you want to import.
- Set the Sync Frequency, indicating how often you want to query your database for new data. You should set the frequency such that sync operations don’t overlap. Learn more about sync frequency.
- Select when you want to start the sync: whether you want to begin importing data immediately, or schedule the sync to start at a later date.
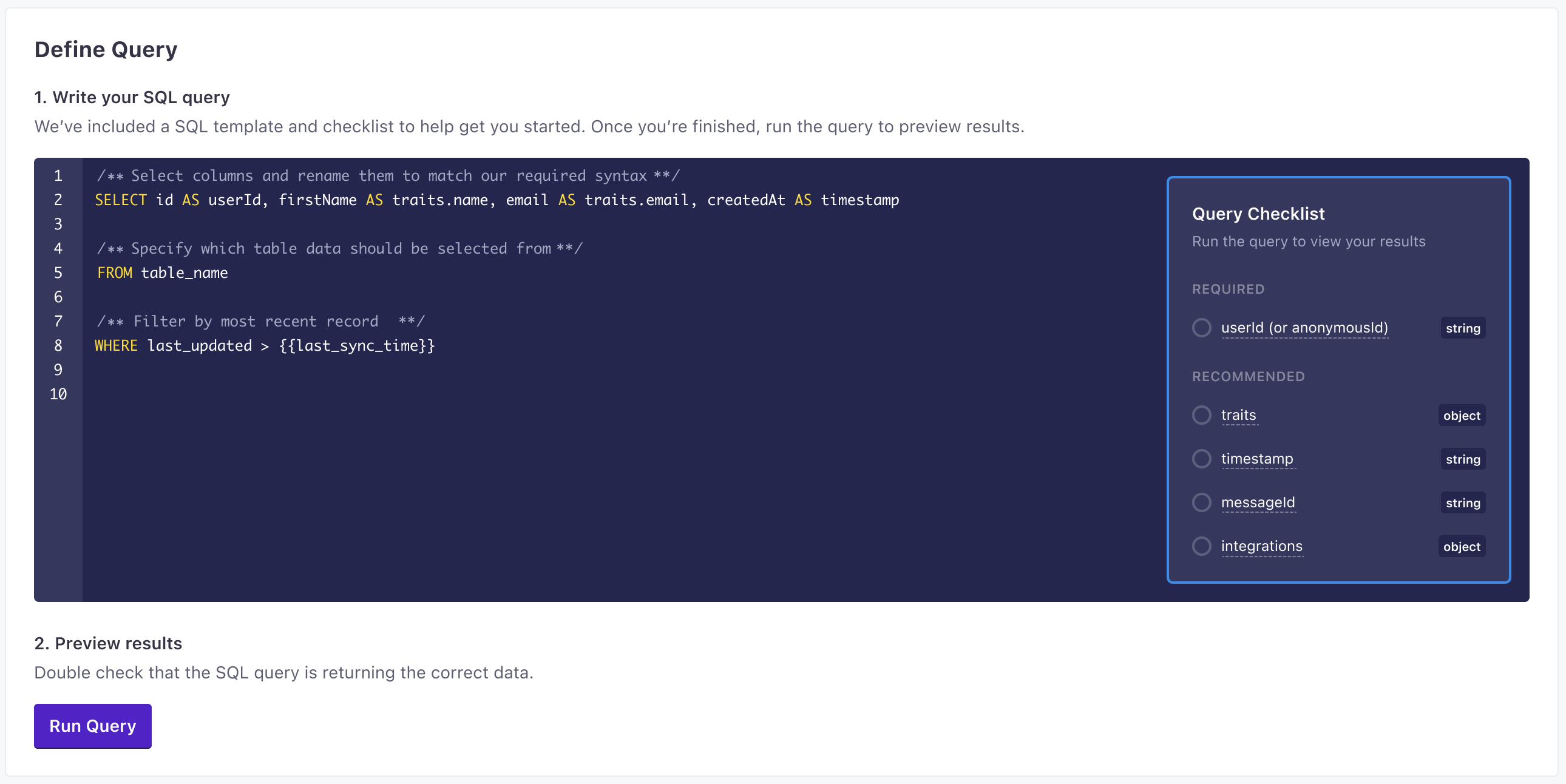
Enter the query that selects the data you want to import. See Queries below for more information about the information you’ll want to select for your sync. Click Run Query to preview results and make sure that your query selects the right information.
Click Enable to enable your sync.
Now you can set up additional syncs and connect your source to one or more destinations.
Adding syncs
After you set up your source, you can add additional syncs to import different types of data from your database. For example, you might want to import identify data for your users, and track data for their actions. Subsequent syncs can rely on your existing database, or you can add another database within your source.
- In your source, go to the Syncs tab and click Add Sync.
- Select your database or add a new one and click Next: Create Sync.
- Set up a syncA sync is the type of source data (
identify,track, etc) you want to import from your database. A sync is essentially the type of source call you want to make. and click Next: Define Query. You can set up syncs for each type of data you want to import.- Provide a Name and Description for the sync. This helps you understand the sync at a glance when you look at your source Overview later.
- Select the type of data you want to import.
- Set the Sync Frequency, indicating how often you want to query your database for new data. You should set the frequency such that sync operations don’t overlap. Learn more about sync frequency.
- Select when you want to start the sync: whether you want to begin importing data immediately, or schedule the sync to start at a later date.
- Enter the query that selects the data you want to import. See Queries below for more information about the information you’ll want to select for your sync. Click Run Query to preview results and make sure that your query selects the right information.
- Click Enable to enable your sync.
Sync Frequency
You can sync data as often as every minute. However, we recommend that you set your sync frequency such that sync operations don’t overlap. If you schedule syncs such that a sync operation is scheduled to start while the previous operation is still we’ll skip the next sync operation.
Queries for each sync type
When you create a database sync, you provide a query selecting the people or objects you want to import, and respective properties. You’ll build your queries using the same principles from our Data Pipelines API.
For billing purposes, each row returned from your query represents an individual source operation/API call. Columns represent the traits or properties that you want to apply to the person, group, or event that your sync imports.
While we support queries that return millions of rows and hundreds of columns, syncing large amounts of data more then once a day can impact your account’s performance—including delaying campaigns or messages. When you set up your query, consider how much data you want to send and how often; and make sure you limit your results using the last_sync_time.
Make sure you compare timestamps against last_sync_time
Our examples below include a last_sync_time value. You must compare a timestamp to this value—or otherwise limit the data you import with each sync—to avoid importing duplicate data, potentially increasing your bill, and potentially impacting your workspace’s performance.
last_sync_time and limiting your results
Because we have to process each incoming row, and charge for each incoming row as an API call, it’s important to limit the amount of data you sync. You can do this by comparing timestamps against the last_sync_time value.
We expose last_time_sync as a Unix timestamp representing the date-time when the previous sync started. By comparing a timestamp against this value, you’ll only sync records that have changed since the last sync.
For your first sync, the last_sync_time is 0, so you’ll sync all records. After that, you’ll just get the changeset.
Identify
The identify method tells Data Pipelines who someone is and lets you assign unique traitsA key-value pair that you associate with a person or an object—like a person’s name, the date they were created in your workspace, or a company’s billing date etc. Use attributes to target people and personalize messages. Attributes are analogous to traits in Data Pipelines. to a person. Your query should compare a timestamp to the last_sync_time to ensure that you only import new data.
You can identify people by anonymousId and/or userId.
anonymousIdonly: This assign traits to a person before you know who they are.userIdonly: Identifies a user and sets traits.- both
userIdandanonymousId: Associates the data from theanonymousIdwith the person you identify byuserId.
SELECT id AS userId, email_address AS email, fname, lname, msisdn AS phone
FROM users
WHERE last_updated >= {{last_sync_time}}- anonymousId stringA unique substitute for a User ID in cases when you don’t have an absolutely unique identifier. Our libraries generate this value automatically to help you track people before they sign up, log in, provide their email, etc.
-
- active boolean
Whether a user is active.
This is usually used when you send an .identify() call to update the traits independently of when you’ve “last seen” a user.
- channel stringThe channel the event originated from.
Accepted values:
browser,server,mobile - ip stringThe user’s IP address. This isn’t captured by our libraries, but by our servers when we receive client-side events (like from our JavaScript source).
- locale stringThe locale string for the current user, e.g.
en-US. - userAgent stringThe user agent of the device making the request
-
- content string
- medium stringThe type of traffic a person/event originates from, like
email, orreferral. - name stringThe campaign name.
- source stringThe source of traffic—like the name of your email list, Facebook, Google, etc.
- term stringThe keyword term(s) a user came from.
- Additional UTM Parameters* string
-
- keywords array of [ strings ]A list/array of keywords describing the page’s content. The keywords are likely the same as, or similar to, the keywords you would find in an HTML
metatag for SEO purposes. This property is mainly used by content publishers that rely heavily on pageview tracking. This isn’t automatically collected. - name stringThe name of the page. Reserved for future use.
- path stringThe path portion of the page’s URL. Equivalent to the canonical
pathwhich defaults tolocation.pathnamefrom the DOM API. - referrer stringThe previous page’s full URL. Equivalent to
document.referrerfrom the DOM API. - search stringThe query string portion of the page’s URL. Equivalent to
location.searchfrom the DOM API. - title stringThe page’s title. Equivalent to
document.titlefrom the DOM API. - url stringA page’s full URL. We first look for the canonical URL. If the canonical URL is not provided, we’ll use
location.hreffrom the DOM API.
-
- Enabled/Disabled integrations* boolean
- timestamp string (date-time)The ISO-8601 timestamp when the event originally took place. This is mostly useful when you backfill data past events. If you’re not backfilling data, you can leave this field empty and we’ll use the current time or server time.
-
- createdAt string (date-time)We recommend that you pass date-time values as ISO 8601 date-time strings. We convert this value to fit destinations where appropriate.
- email stringA person’s email address. In some cases, you can pass an empty
userIdand we’ll use this value to identify a person. - Additional Traits* any typeTraits that you want to set on a person. These can take any JSON shape.
- userId stringThe unique identifier for a person. This value should be unique across systems, so you recognize the same person in your sources and destinations.
Track
The track method records things people do. Every track call represents an event.
You should track your audience’s activities with events both as performance indicators and so you can respond to your audience’s activities with campaignsA series of actions that you perform for each person who matches criteria. Campaigns typically send people a series of messages, but you can also use campaigns to send webhooks, update attributes, etc. in Journeys. For example, if your audience performs a Video Viewed or Item Purchased event, you might respond with other videos or products the person might enjoy.
Track calls require an event name describing what a person did. They must also include an anonymousId or a userId. Calls that you make with an anonymousId are associated with a userId when you identify someone by their userId.
Your query should compare a timestamp to the last_sync_time to ensure that you only import new data.
SELECT id AS userId, event_name AS event, products, total_price AS value
FROM events
WHERE timestamp > {{last_sync_time}}-
- active boolean
Whether a user is active.
This is usually used when you send an .identify() call to update the traits independently of when you’ve “last seen” a user.
- channel stringThe channel the event originated from.
Accepted values:
browser,server,mobile - ip stringThe user’s IP address. This isn’t captured by our libraries, but by our servers when we receive client-side events (like from our JavaScript source).
- locale stringThe locale string for the current user, e.g.
en-US. - userAgent stringThe user agent of the device making the request
-
- content string
- medium stringThe type of traffic a person/event originates from, like
email, orreferral. - name stringThe campaign name.
- source stringThe source of traffic—like the name of your email list, Facebook, Google, etc.
- term stringThe keyword term(s) a user came from.
- Additional UTM Parameters* string
-
- keywords array of [ strings ]A list/array of keywords describing the page’s content. The keywords are likely the same as, or similar to, the keywords you would find in an HTML
metatag for SEO purposes. This property is mainly used by content publishers that rely heavily on pageview tracking. This isn’t automatically collected. - name stringThe name of the page. Reserved for future use.
- path stringThe path portion of the page’s URL. Equivalent to the canonical
pathwhich defaults tolocation.pathnamefrom the DOM API. - referrer stringThe previous page’s full URL. Equivalent to
document.referrerfrom the DOM API. - search stringThe query string portion of the page’s URL. Equivalent to
location.searchfrom the DOM API. - title stringThe page’s title. Equivalent to
document.titlefrom the DOM API. - url stringA page’s full URL. We first look for the canonical URL. If the canonical URL is not provided, we’ll use
location.hreffrom the DOM API.
- event stringRequired The name of the event
-
- Enabled/Disabled integrations* boolean
-
- Event Properties* any typeAdditional properties that you want to capture in the event. These can take any JSON shape.
- timestamp string (date-time)The ISO-8601 timestamp when the event originally took place. This is mostly useful when you backfill data past events. If you’re not backfilling data, you can leave this field empty and we’ll use the current time or server time.
- userId stringRequired The unique identifier for a person. This value should be unique across systems, so you recognize the same person in your sources and destinations.
Group
The Group method associates a person with a group—like a company, organization, project, online class or any other collective noun you come up with for the same concept. In Customer.io Journeys, we call groups objectsNot to be confused with a JSON object, an object in Customer.io is a non-person entity that you can associate with one or more people—like a company, account, or online course. You can use objects to message people based on changes to their company, account, or course itinerary..
Group calls require a groupId to represent the group. In almost every case, a group call should also include a userId to associate the person with the group. You can also include traits to provide additional information about the group (or the relationship between the person and the group). Find more details about the group method in our API specifications.
Your query should compare a timestamp to the last_sync_time to ensure that you only import new data.
Remember, group calls represent both an organization/group and relationships with users (by userId). Your query should include not only the groupId, but the userId so that you can capture relationships at your destinations.
SELECT companyId AS groupId, objectTypeId, companyname, employees, personId AS userId
FROM companies
WHERE last_updated >= {{last_sync_time}} Include objectTypeId if Customer.io Journeys is a destination
Customer.io Journeys lets you set up groups (called objectsNot to be confused with a JSON object, an object in Customer.io is a non-person entity that you can associate with one or more people—like a company, account, or online course. You can use objects to message people based on changes to their company, account, or course itinerary.) of different types; the object type is an incrementing integer beginning at 1. If you use Customer.io Journeys as a destination, you should include the object type ID or we’ll assume that the object type is 1.
-
- active boolean
Whether a user is active.
This is usually used when you send an .identify() call to update the traits independently of when you’ve “last seen” a user.
- channel stringThe channel the event originated from.
Accepted values:
browser,server,mobile - ip stringThe user’s IP address. This isn’t captured by our libraries, but by our servers when we receive client-side events (like from our JavaScript source).
- locale stringThe locale string for the current user, e.g.
en-US. - userAgent stringThe user agent of the device making the request
-
- content string
- medium stringThe type of traffic a person/event originates from, like
email, orreferral. - name stringThe campaign name.
- source stringThe source of traffic—like the name of your email list, Facebook, Google, etc.
- term stringThe keyword term(s) a user came from.
- Additional UTM Parameters* string
-
- keywords array of [ strings ]A list/array of keywords describing the page’s content. The keywords are likely the same as, or similar to, the keywords you would find in an HTML
metatag for SEO purposes. This property is mainly used by content publishers that rely heavily on pageview tracking. This isn’t automatically collected. - name stringThe name of the page. Reserved for future use.
- path stringThe path portion of the page’s URL. Equivalent to the canonical
pathwhich defaults tolocation.pathnamefrom the DOM API. - referrer stringThe previous page’s full URL. Equivalent to
document.referrerfrom the DOM API. - search stringThe query string portion of the page’s URL. Equivalent to
location.searchfrom the DOM API. - title stringThe page’s title. Equivalent to
document.titlefrom the DOM API. - url stringA page’s full URL. We first look for the canonical URL. If the canonical URL is not provided, we’ll use
location.hreffrom the DOM API.
- groupId stringRequired ID of the group
-
- Enabled/Disabled integrations* boolean
- objectTypeId string
If you use Customer.io Journeys as a destination, this value is the type of group/object your group belongs to; object type IDs are stringified integers. If you don’t include this value, we assume the object type ID is
1. See objects in Customer.io Journeys for more information.You can include this value as
objectTypeIdat the top level of your payload or asobject_type_idin thetraitsobject. - timestamp string (date-time)The ISO-8601 timestamp when the event originally took place. This is mostly useful when you backfill data past events. If you’re not backfilling data, you can leave this field empty and we’ll use the current time or server time.
-
- object_type_id string
If you use Customer.io Journeys as a destination, this value is the type of group/object your group belongs to; object type IDs are stringified integers. If you don’t include this value, we assume the object type ID is
1. See objects in Customer.io Journeys for more information.You can include this value as
objectTypeIdat the top level of your payload or asobject_type_idin thetraitsobject. - Group Traits* any typeAdditional traits you want to associate with this group.
- userId stringThe unique identifier for a person. This value should be unique across systems, so you recognize the same person in your sources and destinations.
Page
The Page method records page views on your website, along with optional extra information about the page a person visited.
Your query should compare a timestamp to the last_sync_time to ensure that you only import new data.
SELECT id AS userId, metatitle as name, url, time_on_page
FROM pages
WHERE timestamp > {{last_sync_time}}-
- active boolean
Whether a user is active.
This is usually used when you send an .identify() call to update the traits independently of when you’ve “last seen” a user.
- channel stringThe channel the event originated from.
Accepted values:
browser,server,mobile - ip stringThe user’s IP address. This isn’t captured by our libraries, but by our servers when we receive client-side events (like from our JavaScript source).
- locale stringThe locale string for the current user, e.g.
en-US. - userAgent stringThe user agent of the device making the request
-
- content string
- medium stringThe type of traffic a person/event originates from, like
email, orreferral. - name stringThe campaign name.
- source stringThe source of traffic—like the name of your email list, Facebook, Google, etc.
- term stringThe keyword term(s) a user came from.
- Additional UTM Parameters* string
-
- keywords array of [ strings ]A list/array of keywords describing the page’s content. The keywords are likely the same as, or similar to, the keywords you would find in an HTML
metatag for SEO purposes. This property is mainly used by content publishers that rely heavily on pageview tracking. This isn’t automatically collected. - name stringThe name of the page. Reserved for future use.
- path stringThe path portion of the page’s URL. Equivalent to the canonical
pathwhich defaults tolocation.pathnamefrom the DOM API. - referrer stringThe previous page’s full URL. Equivalent to
document.referrerfrom the DOM API. - search stringThe query string portion of the page’s URL. Equivalent to
location.searchfrom the DOM API. - title stringThe page’s title. Equivalent to
document.titlefrom the DOM API. - url stringA page’s full URL. We first look for the canonical URL. If the canonical URL is not provided, we’ll use
location.hreffrom the DOM API.
-
- Enabled/Disabled integrations* boolean
- name stringRequired The name of the page.
-
- category stringThe category of the page. This might be useful if you have a single page routes or have a flattened URL structure.
- Page Properties* any typeAdditional properties tha tyou want to send with the page event. By default, we capture `url`, `title`, and stuff.
- timestamp string (date-time)The ISO-8601 timestamp when the event originally took place. This is mostly useful when you backfill data past events. If you’re not backfilling data, you can leave this field empty and we’ll use the current time or server time.
- userId stringRequired The unique identifier for a person. This value should be unique across systems, so you recognize the same person in your sources and destinations.
Screen
The Screen method sends screen view events for mobile devices. These help you understand the screens that people use in your app.
Your query should compare a timestamp to the last_sync_time to ensure that you only import new data.
SELECT id AS userId, screen_name as name, session_started
FROM screens
WHERE timestamp > {{last_sync_time}}-
- active boolean
Whether a user is active.
This is usually used when you send an .identify() call to update the traits independently of when you’ve “last seen” a user.
- channel stringThe channel the event originated from.
Accepted values:
browser,server,mobile - ip stringThe user’s IP address. This isn’t captured by our libraries, but by our servers when we receive client-side events (like from our JavaScript source).
- locale stringThe locale string for the current user, e.g.
en-US. - userAgent stringThe user agent of the device making the request
-
- build stringThe specific build number in the app.
- name stringThe name of the app.
- namespace stringThe app’s namespace.
- version stringThe version of the app the call originated from.
-
- advertisingId stringThe advertising ID is a unique, anonymous ID for advertising.
- id stringThe device ID.
- manufacturer stringThe device manufacturer.
- model stringThe device model.
- name stringThe device name.
- type stringThe device type—android, iOS, etc.
Accepted values:
android,ios - version stringThe firmware version for the device.
-
- bluetooth booleanLets you know if bluetooth is enabled on a device.
- carrier stringThe cellular carrier the phone uses.
- cellular booleanIndicates whether the device’s cellular connection is enabled or not.
- wifi booleanIndicates whether a device’s wifi connection is enabled or not.
-
- name stringThe operating system running on the device.
- version stringThe version of the OS running on the device.
-
- Enabled/Disabled integrations* boolean
- name stringRequired The name of the screen the person visited.
- timestamp string (date-time)The ISO-8601 timestamp when the event originally took place. This is mostly useful when you backfill data past events. If you’re not backfilling data, you can leave this field empty and we’ll use the current time or server time.
- userId stringRequired The unique identifier for a person. This value should be unique across systems, so you recognize the same person in your sources and destinations.
Alias
The Alias method combines two previously unassociated user identities. Some destinations automatically reconcile profiles with different identifiers based on whether you send anonymousId, userId, or another trait that the destination expects to be unique. But for destinations that don’t, you may need to send alias requests to do this.
In general, you won’t need to use the alias call; we try to handle user identification gracefully, so that you don’t need to merge profiles. But you may need to send alias calls to manage user identities in some destinations.
For example, in Mixpanel it’s used to associate an anonymous user with an identified user once they sign up.
SELECT id AS userId, old_id as previousId
FROM user_resolution
WHERE timestamp >= {{last_sync_time}}- previousId stringRequired The userId that you want to merge into the canonical profile.
- userId stringRequired The userId that you want to keep. This is required if you haven’t already identified someone with one of our web or server-side libraries.

